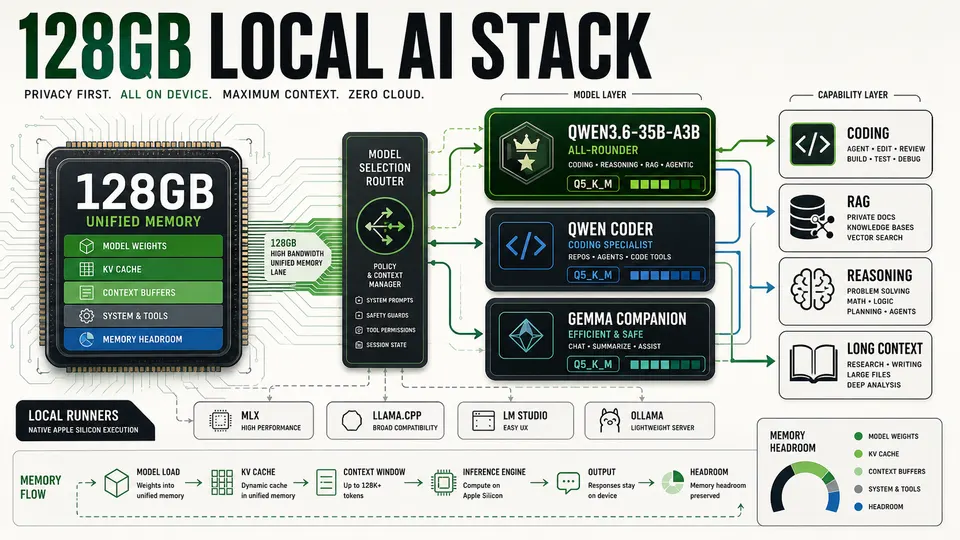
Qwen3.6-35B-A3B leads 2026 open-weight AI picks for 128GB Apple Silicon Macs, balancing coding, reasoning, long context and local speed for developers.
If you want one open-weight model for a 128GB Apple Silicon Mac in May 2026, start with Qwen3.6-35B-A3B at Q5_K_M. It offers the best verified balance of coding, reasoning, tool use and long-context practicality; use Qwen3-Coder-30B-A3B-Instruct when pure coding speed matters more.
The local AI market has shifted. The practical question for Mac users is no longer whether a 128GB machine can run a serious model. It can. The sharper question is whether users should chase older 70B dense models, very large sparse models, or the newer 30B-35B efficient MoE class that preserves speed, context and reliability.
For most developers, researchers and private-AI users, the answer is now clear: Qwen3.6-35B-A3B is the best default local model for a high-memory Apple Silicon Mac. The model has 35.95B total parameters, uses a mixture-of-experts architecture, supports a 262,144-token native context window, can extend further with YaRN, and is released under Apache-2.0. Its published coding-agent results include 73.4 on SWE-bench Verified, 49.5 on SWE-bench Pro and 51.5 on Terminal-Bench 2.0.
That combination matters because local Mac inference is not just a memory-size contest. Agentic coding, repo analysis and RAG workloads repeatedly push large prompts, tool outputs, diffs and logs through the model. A smaller model with strong tool use and long-context discipline can outperform a larger model that technically fits but runs slowly, leaves little context headroom or behaves unreliably inside an IDE loop.
The Best Current Shortlist
| Model | Parameters | Architecture | Context | License | 128GB Mac verdict |
|---|---|---|---|---|---|
| Qwen3.6-35B-A3B | 35.95B total | MoE | 262,144 native; extendable with YaRN | Apache-2.0 | Best overall local model |
| Qwen3-Coder-30B-A3B-Instruct | 30.5B total / 3.3B active | MoE | 262,144 native; up to 1M with YaRN | Apache-2.0 | Best practical coding specialist |
| Qwen3-Coder-Next | 80B total / 3B active | Hybrid MoE | 256K-class deployment context | Apache-2.0 | Strong hard-task coder, heavier locally |
| Gemma 4 31B IT | 30.7B dense | Dense multimodal | 256K | Apache-2.0 | Best dense fallback |
| Gemma 4 26B A4B IT | 25.2B total / 3.8B active | MoE multimodal | 256K | Apache-2.0 | Best fast model |
| DeepSeek-V4-Flash | 284B total / 13B active | MoE | 1M | MIT | Better as remote/API than local daily driver |
The top row is the important correction to older advice. A generic "Qwen3-Coder 30B-class" recommendation is now incomplete. Qwen3-Coder-30B-A3B-Instruct remains excellent for coding, but Qwen3.6-35B-A3B is the stronger all-rounder because it combines coding-agent strength with broader reasoning, multimodal support, tool calling and long-context behavior.
Why 30B-35B MoE Is the 128GB Sweet Spot
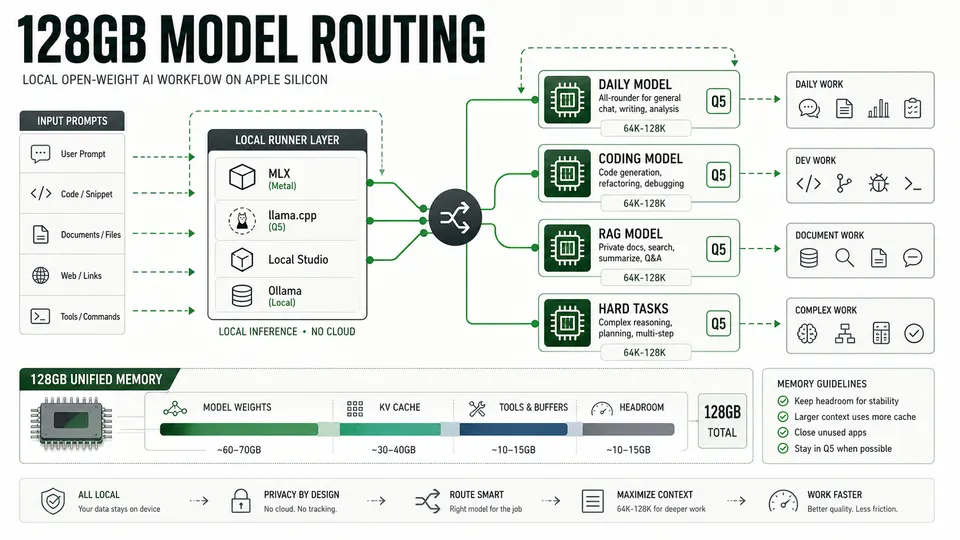
A 128GB Apple Silicon Mac has enough unified memory to run large open-weight models, but every part of the stack competes for the same memory pool: model weights, KV cache, macOS, browser tabs, IDEs, Docker containers, vector databases and local serving processes.
That is why the 2026 sweet spot has moved away from treating classic 70B dense models as the automatic quality target. A 70B dense model at useful quantization can still be valuable, especially for hard reasoning or review work, but the newer 30B-35B MoE models often deliver a better daily balance: faster prompt handling, more practical context, lower memory pressure and better responsiveness in agentic workflows.
The key trade-off is context. A model card may advertise 256K or 1M tokens, but long context is not free. KV cache growth, prompt-processing latency and runner maturity can dominate the experience. For local use, 64K-128K is the sensible daily range for serious coding and RAG. A 256K context window should be reserved for tasks that genuinely require it.
Coding and Agentic Workflows
For everyday coding, Qwen3-Coder-30B-A3B-Instruct is the sharper specialist. It has 30.5B total parameters, activates 3.3B, supports 262,144 tokens natively, and can extend to 1M tokens with YaRN. It is designed for repository-scale understanding and tool-driven coding environments.
But the best daily model for a mixed workload is still Qwen3.6-35B-A3B. It is strong enough for code review, refactoring, frontend workflows and repository-level reasoning, while remaining broad enough for research, document analysis and private assistant use.
Qwen3-Coder-Next sits in a different role. With 80B total parameters but only 3B active, it is a serious coding-agent model for hard tasks. It is not the model most Mac users should keep as the default daily driver because its total footprint and long-context behavior make it heavier to run locally.
Gemma's Role: Dense Stability and Multimodal Work
Google's Gemma 4 31B IT is the best dense alternative in this lineup. It has 30.7B dense parameters, a 256K context window, multimodal input support and strong reasoning benchmarks, including 85.2 on MMLU-Pro, 84.3 on GPQA Diamond and 80.0 on LiveCodeBench v6.
Its sibling, Gemma 4 26B A4B IT, is the fast option. It has 25.2B total parameters and 3.8B active parameters, with a 256K context window. It will not replace Qwen3.6 as the best all-rounder, but it is attractive for lower-latency chat, RAG, document extraction and multimodal assistant use.
Planning Estimates for Apple Silicon
The following are directional planning estimates, not verified benchmarks. Actual throughput depends on runner, quantization, prompt length, thermal state, batch size and whether the architecture is optimized in MLX, llama.cpp or Ollama.
| Model | Likely local role | Practical context target | Planning speed expectation |
|---|---|---|---|
| Qwen3.6-35B-A3B Q5_K_M | Daily all-rounder | 64K-128K | Fast enough for interactive coding |
| Qwen3-Coder-30B-A3B Q5_K_M | Coding specialist | 64K-128K | Faster coding loop than larger models |
| Gemma 4 26B A4B | Fast assistant/RAG | 64K-128K | Best responsiveness among top picks |
| Gemma 4 31B | Dense fallback | 32K-96K | Stable but heavier than active-light MoE |
| Qwen3-Coder-Next | Hard coding tasks | 32K-64K | Capable but slower locally |
Daily Model, Hard-Task Model and Buying Advice
For a 128GB Mac, use Qwen3.6-35B-A3B at Q5_K_M as the daily model. It is the best single choice for coding, code review, local RAG, long-context research and private assistant work.
Use Qwen3-Coder-30B-A3B-Instruct when you want a faster coding-focused loop, especially in IDE agents or terminal coding tools. Use Qwen3-Coder-Next only when a task is complex enough to justify the extra local weight.
For buyers, 128GB is enough for serious local AI if the goal is one strong model at a time with practical long context and normal developer workloads. Choose 256GB if you want multiple models loaded, heavier 80B+ experiments, very long context, or a local server with databases, containers and concurrent users.
The broader implication is simple: the best 128GB Mac setup in 2026 is not a laptop pretending to be a datacenter. It is a focused workstation built around one excellent 30B-35B efficient model, a fast coding specialist and a disciplined context strategy. On that basis, Qwen3.6-35B-A3B is the model to beat.